Probability theory and basic concepts of the theory. Binomial distribution of a discrete random variable
Binomial distribution- one of the most important probability distributions of a discretely changing random variable. The binomial distribution is the probability distribution of the number m occurrence of an event A V n mutually independent observations. Often an event A is called the “success” of an observation, and the opposite event is called “failure,” but this designation is very conditional.
Binomial distribution conditions:
- V total carried out n trials in which the event A may or may not occur;
- event A in each test can occur with the same probability p;
- tests are mutually independent.
The probability that in n testing event A it will come exactly m times, can be calculated using Bernoulli's formula:
![]()
![]() ,
,
Where p- probability of an event occurring A;
q = 1 - p- the probability of the opposite event occurring.
Let's figure it out why is the binomial distribution related to Bernoulli's formula in the manner described above? . Event - number of successes at n tests are divided into a number of options, in each of which success is achieved in m tests, and failure - in n - m tests. Let's consider one of these options - B1 . Using the rule for adding probabilities, we multiply the probabilities of opposite events:
![]() ,
,
and if we denote q = 1 - p, That
![]() .
.
Any other option in which m success and n - m failures. The number of such options is equal to the number of ways in which one can n test get m success.
Sum of all probabilities m event occurrence numbers A(numbers from 0 to n) is equal to one:
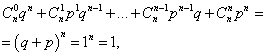
where each term represents a term in Newton's binomial. Therefore, the distribution under consideration is called the binomial distribution.
In practice, it is often necessary to calculate probabilities "no more than m success in n tests" or "at least m success in n tests". The following formulas are used for this.
The integral function, that is probability F(m) what's in n observational event A no more will come m once, can be calculated using the formula:
In its turn probability F(≥m) what's in n observational event A will come no less m once, is calculated by the formula:
Sometimes it is more convenient to calculate the probability that n observational event A no more will come m times, through the probability of the opposite event:
![]() .
.
Which formula to use depends on which of them has the sum containing fewer terms.
The characteristics of the binomial distribution are calculated using the following formulas .
Expected value: .
Dispersion: .
Standard deviation: .
Binomial distribution and calculations in MS Excel
Binomial probability P n ( m) and the values of the integral function F(m) can be calculated using the MS Excel function BINOM.DIST. The window for the corresponding calculation is shown below (left click to enlarge).

MS Excel requires you to enter the following data:
- number of successes;
- number of tests;
- probability of success;
- integral - logical value: 0 - if you need to calculate the probability P n ( m) and 1 - if the probability F(m).
Example 1. The company manager summarized information on the number of cameras sold over the last 100 days. The table summarizes the information and calculates the probabilities that a certain number of cameras will be sold per day.
The day ends with a profit if 13 or more cameras are sold. Probability that the day will be worked out profitably:
![]()
Probability that a day will be worked without profit:

Let the probability that a day is worked with a profit be constant and equal to 0.61, and the number of cameras sold per day does not depend on the day. Then we can use the binomial distribution, where the event A- the day will be worked with profit, - without profit.
Probability that all 6 days will be worked out with profit:
![]() .
.
We get the same result using the MS Excel function BINOM.DIST (the value of the integral value is 0):
P 6 (6 ) = BINOM.DIST(6; 6; 0.61; 0) = 0.052.
The probability that out of 6 days 4 and more days will be worked out at a profit:
Where ![]() ,
,
![]() ,
,
Using the MS Excel function BINOM.DIST, we calculate the probability that out of 6 days no more than 3 days will be completed with a profit (the value of the integral value is 1):
P 6 (≤3 ) = BINOM.DIST(3; 6; 0.61; 1) = 0.435.
Probability that all 6 days will be worked out with losses:
![]() ,
,
We can calculate the same indicator using the MS Excel function BINOM.DIST:
P 6 (0 ) = BINOM.DIST(0; 6; 0.61; 0) = 0.0035.
Solve the problem yourself and then see the solution
Example 2. There are 2 white balls and 3 black balls in the urn. A ball is taken out of the urn, the color is set and put back. The attempt is repeated 5 times. The number of occurrences of white balls is a discrete random variable X, distributed according to the binomial law. Draw up a law of distribution of a random variable. Define mode, mathematical expectation and dispersion.
Let's continue to solve problems together
Example 3. From the courier service we went to the sites n= 5 couriers. Each courier is likely p= 0.3, regardless of others, is late for the object. Discrete random variable X- number of late couriers. Construct a distribution series for this random variable. Find its mathematical expectation, variance, standard deviation. Find the probability that at least two couriers will be late for the objects.
Random event is any fact that may or may not occur as a result of the test. A random event is the result of a test. Trial– this is an experiment, the fulfillment of a certain set of conditions in which this or that phenomenon is observed, this or that result is recorded.
Events are designated by capital letters of the Latin alphabet A, B, C.
The numerical measure of the degree of objectivity of the possibility of an event occurring is called the probability of a random event.
Classic definition probability of event A:
The probability of event A is equal to the ratio of the number of cases favorable to event A(m) to total number cases (n).
Statistical definition probabilities
Relative frequency of events– this is the proportion of those actually conducted tests in which event A appeared W=P*(A)= m/n. This is an experimental characteristic, where m is the number of experiments in which event A appeared; n is the number of all experiments performed.
Probability of the event is the number around which the frequency values of a given event in different series are grouped large number tests P(A)=.
The events are called incompatible, if the occurrence of one of them excludes the occurrence of the other. Otherwise the events are joint.
Sum two events is an event in which at least one of these events (A or B) occurs.
If A and B joint events, then their sum A+B indicates the occurrence of event A or event B, or both events together.
If A and B incompatible events, then the sum A+B means the occurrence of either event A or event B.
2. The concept of dependent and independent events. Conditional probability, law (theorem) of multiplication of probabilities. Bayes' formula.
Event B is called independent from event A, if the occurrence of event A does not change the probability of the occurrence of event B. The probability of the occurrence of several independent events is equal to the product of the probabilities of these:
P(AB) = P(A)*P(B)
For dependent events:
P(AB) = P(A)*P(B/A).
The probability of two events occurring is equal to the product of the probability of one of them and the conditional probability of the other, found under the assumption that the first event occurred.
Conditional probability event B is the probability of event B found given that event A occurred. Denoted by P(V/A)
Work two events is an event consisting of the joint occurrence of these events (A and B)
Bayes' formula is used to re-estimate random events
P(H/A) = (P(H)*P(A/H))/P(A)
P(H) – prior probability of event H
P(H/A) – posterior probability of hypothesis H, provided that event A has already occurred
P(A/H) – expert assessment
P(A) – total probability of event A
3. Distribution of discrete and continuous random variables and their characteristics: mathematical expectation, dispersion, standard deviation. Normal distribution law of continuous random variables.
Random value is a quantity that, as a result of testing, depending on the case, takes on one of its possible many values.
Discrete random variable– it is a random variable when it takes on a single, isolated, countable set of values.
Continuous random variable is a random variable that takes any values from a certain interval. The concept of a continuous random variable arises in measurements.
For discrete random variable, the distribution law can be specified in the form tables, analytically (in the form of a formula) and graphically.
Table– this is the simplest form of specifying the distribution law
Requirements:
for discrete random variables
Analytical:
1)F(x)=P(X Distribution function = cumulative distribution function. For discrete and continuous random variables. 2)f(x) = F’(x) Probability density function = differential distribution function for a continuous random variable only. Graphic: Conditions: 1) 0≤F(x)≤1 2) non-decreasing for discrete random variables S-va: 1) f(x)≥0 P(x)= 2) area S=1 for continuous random variables Characteristics: 1.mathematical expectation – average most probable event For discrete random variables. For continuous random variables. 2) Dispersion - scattering around the mathematical expectation For discrete random variables: D(x)=x i -M(x)) 2 *p i For continuous random variables: D(x)=x-M(x)) 2 *f(x)dx 3) Standard deviation: σ(x)=√(D(x)) σ – standard deviation or standard x is the arithmetic value of the square root of its variance Normal distribution law (NDL) - Gauss's law NZR is the decay of the probabilities of a continuous random variable, which is described by the differential function Probability theory is a branch of mathematics that studies the patterns of random phenomena: random events, random variables, their properties and operations on them. For a long time, probability theory did not have a clear definition. It was formulated only in 1929. The emergence of probability theory as a science dates back to the Middle Ages and the first attempts at mathematical analysis of gambling (flake, dice, roulette). French mathematicians of the 17th century Blaise Pascal and Pierre Fermat, while studying the prediction of winnings in gambling, discovered the first probabilistic patterns that arise when throwing dice. Probability theory arose as a science from the belief that mass random events are based on certain patterns. Probability theory studies these patterns. Probability theory deals with the study of events whose occurrence is not known with certainty. It allows you to judge the degree of probability of the occurrence of some events compared to others. For example: it is impossible to determine unambiguously the result of “heads” or “tails” as a result of tossing a coin, but with repeated tossing, approximately the same number of “heads” and “tails” appear, which means that the probability that “heads” or “tails” will fall ", is equal to 50%. Test in this case, the implementation of a certain set of conditions is called, that is, in this case, the toss of a coin. The challenge can be played an unlimited number of times. In this case, the set of conditions includes random factors. The test result is event. The event happens: For example, when tossing a coin, an impossible event - the coin will land on its edge, a random event - the appearance of “heads” or “tails”. The specific test result is called elementary event. As a result of the test, only elementary events occur. The set of all possible, different, specific test outcomes is called space of elementary events. Probability- the degree of possibility of the occurrence of an event. When the reasons for some possible event to actually occur outweigh the opposite reasons, then this event is called probable, otherwise - unlikely or improbable. Random value- this is a quantity that, as a result of testing, can take one or another value, and it is not known in advance which one. For example: number per fire station per day, number of hits with 10 shots, etc. Random variables can be divided into two categories. Probability space- concept introduced by A.N. Kolmogorov in the 30s of the 20th century to formalize the concept of probability, which gave rise to the rapid development of probability theory as a strict mathematical discipline. A probability space is a triple (sometimes enclosed in angle brackets: , where This is an arbitrary set, the elements of which are called elementary events, outcomes or points; De Moivre-Laplace theorem- one of the limit theorems of probability theory, established by Laplace in 1812. It states that the number of successes when repeating the same random experiment over and over again with two possible outcomes is approximately normally distributed. It allows you to find an approximate probability value. If for each of the independent trials the probability of the occurrence of some random event is equal to () and is the number of trials in which it actually occurs, then the probability of the inequality being true is close (for large values) to the value of the Laplace integral. Distribution function in probability theory- a function characterizing the distribution of a random variable or random vector; the probability that a random variable X will take a value less than or equal to x, where x is an arbitrary real number. If known conditions are met, it completely determines the random variable. Expected value- the average value of a random variable (this is the probability distribution of a random variable, considered in probability theory). In English-language literature it is denoted by , in Russian - . In statistics, the notation is often used. Let a probability space and a random variable defined on it be given. That is, by definition, a measurable function. Then, if there is a Lebesgue integral of over space, then it is called the mathematical expectation, or the mean value, and is denoted . Variance of a random variable- a measure of the spread of a given random variable, i.e. its deviation from the mathematical expectation. It is designated in Russian and foreign literature. In statistics, the notation or is often used. The square root of the variance is called the standard deviation, standard deviation, or standard spread. Let be a random variable defined on some probability space. Then where the symbol denotes the mathematical expectation. In probability theory, two random events are called independent, if the occurrence of one of them does not change the probability of the occurrence of the other. Similarly, two random variables are called dependent, if the value of one of them affects the probability of the values of the other. The simplest form of the law of large numbers is Bernoulli's theorem, which states that if the probability of an event is the same in all trials, then as the number of trials increases, the frequency of the event tends to the probability of the event and ceases to be random. The law of large numbers in probability theory states that the arithmetic mean of a finite sample from a fixed distribution is close to the theoretical mean of that distribution. Depending on the type of convergence, a distinction is made between the weak law of large numbers, when convergence occurs by probability, and the strong law of large numbers, when convergence is almost certain. The general meaning of the law of large numbers is that the joint action of a large number of identical and independent random factors leads to a result that, in the limit, does not depend on chance. Methods for estimating probability based on finite sample analysis are based on this property. A clear example is the forecast of election results based on a survey of a sample of voters. Central limit theorems- a class of theorems in probability theory stating that the sum of a sufficiently large number of weakly dependent random variables that have approximately the same scales (none of the terms dominates or makes a determining contribution to the sum) has a distribution close to normal. Since many random variables in applications are formed under the influence of several weakly dependent random factors, their distribution is considered normal. In this case, the condition must be met that none of the factors is dominant. Central limit theorems in these cases justify the use of the normal distribution. In practice, most random variables that are influenced by a large number of random factors obey the normal probability distribution law. Therefore, in various applications of probability theory, this law is of particular importance. The random variable $X$ obeys the normal probability distribution law if its probability distribution density has the following form $$f\left(x\right)=((1)\over (\sigma \sqrt(2\pi )))e^(-(((\left(x-a\right))^2)\over ( 2(\sigma )^2)))$$ The graph of the function $f\left(x\right)$ is shown schematically in the figure and is called “Gaussian curve”. To the right of this graph is the German 10 mark banknote, which was used before the introduction of the euro. If you look closely, you can see on this banknote the Gaussian curve and its discoverer, the greatest mathematician Carl Friedrich Gauss. Let's return to our density function $f\left(x\right)$ and give some explanations regarding the distribution parameters $a,\ (\sigma )^2$. The parameter $a$ characterizes the center of dispersion of the values of a random variable, that is, it has the meaning of a mathematical expectation. When the parameter $a$ changes and the parameter $(\sigma )^2$ remains unchanged, we can observe a shift in the graph of the function $f\left(x\right)$ along the abscissa, while the density graph itself does not change its shape. The parameter $(\sigma )^2$ is the variance and characterizes the shape of the density graph curve $f\left(x\right)$. When changing the parameter $(\sigma )^2$ with the parameter $a$ unchanged, we can observe how the density graph changes its shape, compressing or stretching, without moving along the abscissa axis. As is known, the probability of a random variable $X$ falling into the interval $\left(\alpha ;\ \beta \right)$ can be calculated $P\left(\alpha< X < \beta \right)=\int^{\beta }_{\alpha }{f\left(x\right)dx}$. Для нормального распределения случайной величины $X$ с параметрами $a,\ \sigma $ справедлива следующая формула: $$P\left(\alpha< X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right)$$ Here the function $\Phi \left(x\right)=((1)\over (\sqrt(2\pi )))\int^x_0(e^(-t^2/2)dt)$ is the Laplace function . The values of this function are taken from . The following properties of the function $\Phi \left(x\right)$ can be noted. 1
. $\Phi \left(-x\right)=-\Phi \left(x\right)$, that is, the function $\Phi \left(x\right)$ is odd. 2
. $\Phi \left(x\right)$ is a monotonically increasing function. 3
. $(\mathop(lim)_(x\to +\infty ) \Phi \left(x\right)\ )=0.5$, $(\mathop(lim)_(x\to -\infty ) \ Phi \left(x\right)\ )=-0.5$. To calculate the values of the function $\Phi \left(x\right)$, you can also use the function $f_x$ wizard in Excel: $\Phi \left(x\right)=NORMDIST\left(x;0;1;1\right )-0.5$. For example, let's calculate the values of the function $\Phi \left(x\right)$ for $x=2$. The probability of a normally distributed random variable $X\in N\left(a;\ (\sigma )^2\right)$ falling into an interval symmetric with respect to the mathematical expectation $a$ can be calculated using the formula $$P\left(\left|X-a\right|< \delta \right)=2\Phi \left({{\delta }\over {\sigma }}\right).$$ Three sigma rule. It is almost certain that a normally distributed random variable $X$ will fall into the interval $\left(a-3\sigma ;a+3\sigma \right)$. Example 1
. The random variable $X$ is subject to the normal probability distribution law with parameters $a=2,\ \sigma =3$. Find the probability of $X$ falling into the interval $\left(0.5;1\right)$ and the probability of satisfying the inequality $\left|X-a\right|< 0,2$. Using formula $$P\left(\alpha< X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right),$$ we find $P\left(0.5;1\right)=\Phi \left(((1-2)\over (3))\right)-\Phi \left(((0.5-2)\ over (3))\right)=\Phi \left(-0.33\right)-\Phi \left(-0.5\right)=\Phi \left(0.5\right)-\Phi \ left(0.33\right)=0.191-0.129=$0.062. $$P\left(\left|X-a\right|< 0,2\right)=2\Phi \left({{\delta }\over {\sigma }}\right)=2\Phi \left({{0,2}\over {3}}\right)=2\Phi \left(0,07\right)=2\cdot 0,028=0,056.$$ Example 2
. Suppose that during the year the price of shares of a certain company is a random variable distributed according to the normal law with a mathematical expectation equal to 50 conventional monetary units and a standard deviation equal to 10. What is the probability that on a randomly selected day of the period under discussion the price for the promotion will be: a) more than 70 conventional monetary units? b) below 50 per share? c) between 45 and 58 conventional monetary units per share? Let the random variable $X$ be the price of shares of some company. By condition, $X$ is subject to a normal distribution with parameters $a=50$ - mathematical expectation, $\sigma =10$ - standard deviation. Probability $P\left(\alpha< X < \beta \right)$ попадания $X$ в интервал $\left(\alpha ,\ \beta \right)$ будем находить по формуле: $$P\left(\alpha< X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right).$$ $$а)\ P\left(X>70\right)=\Phi \left(((\infty -50)\over (10))\right)-\Phi \left(((70-50)\ over (10))\right)=0.5-\Phi \left(2\right)=0.5-0.4772=0.0228.$$ $$b)\P\left(X< 50\right)=\Phi \left({{50-50}\over {10}}\right)-\Phi \left({{-\infty -50}\over {10}}\right)=\Phi \left(0\right)+0,5=0+0,5=0,5.$$ $$in)\ P\left(45< X < 58\right)=\Phi \left({{58-50}\over {10}}\right)-\Phi \left({{45-50}\over {10}}\right)=\Phi \left(0,8\right)-\Phi \left(-0,5\right)=\Phi \left(0,8\right)+\Phi \left(0,5\right)=$$ Despite their exotic names, common distributions relate to each other in intuitive and interesting ways that make them easy to remember and reason about with confidence. Some follow naturally, for example, from the Bernoulli distribution. Time to show a map of these connections. Each distribution is illustrated by an example of its distribution density function (DFF). This article is only about those distributions whose outcomes are single numbers. Therefore, the horizontal axis of each graph is a set of possible outcome numbers. Vertical – the probability of each outcome. Some distributions are discrete - their outcomes must be integers, such as 0 or 5. These are indicated by sparse lines, one for each outcome, with a height corresponding to the probability of a given outcome. Some are continuous, their outcomes can take on any numerical value, such as -1.32 or 0.005. These are shown as dense curves with areas under the sections of the curve that give probabilities. The sum of the heights of lines and areas under curves is always 1. Print, cut according dotted line and carry it with you in your wallet. This is your guide to the country of distributions and their relatives. The Bernoulli distribution can also represent unequally probable outcomes, such as flipping an incorrect coin. Then the probability of heads will not be 0.5, but some other value p, and the probability of tails will be 1-p. Like many other distributions, this is actually a whole family of distributions given by certain parameters, as p above. When you think “Bernoulli”, think about “tossing a (possibly wrong) coin.” From here it is a very small step to represent the distribution on top of several equally probable outcomes: a uniform distribution characterized by a flat PDF. Imagine a regular dice. Its outcomes 1-6 are equally probable. It can be specified for any number of outcomes n, and even as a continuous distribution. Think of an even distribution as a “straight die.” Toss a fair coin twice - how many times will it be heads? This is a number that follows the binomial distribution. Its parameters are n, the number of trials, and p – the probability of “success” (in our case, heads or 1). Each throw is a Bernoulli-distributed outcome, or test. Use the binomial distribution when counting the number of successes in things like tossing a coin, where each toss is independent of the others and has the same probability of success. Or imagine an urn with the same number of white and black balls. Close your eyes, take out the ball, write down its color and put it back. Repeat. How many times is the black ball drawn? This number also follows the binomial distribution. We presented this strange situation to make it easier to understand the meaning of the hypergeometric distribution. This is the distribution of the same number, but in the situation if we Not returned the balls. It certainly cousin binomial distribution, but not the same, since the probability of success changes with each ball drawn. If the number of balls is large enough compared to the number of draws, then these distributions are almost identical, since the chance of success changes extremely slightly with each draw. When someone talks about pulling balls out of urns without returning them, it is almost always safe to say “yes, hypergeometric distribution,” because I have never met anyone in my life who actually filled urns with balls and then pulled them out and returned them, or vice versa. I don’t even know anyone with trash cans. Even more often, this distribution should emerge when selecting a significant subset of some population as a sample. Note translation It may not be very clear here, but since the tutorial is an express course for beginners, it should be clarified. The population is something that we want to statistically evaluate. To estimate, we select a certain part (subset) and make the required estimate on it (then this subset is called a sample), assuming that the estimate for the entire population will be similar. But for this to be true, additional restrictions are often required on the definition of a subset of the sample (or, conversely, given a known sample, we need to assess whether it sufficiently accurately describes the population). A practical example - we need to select representatives from a company of 100 people to travel to E3. It is known that 10 people already traveled there last year (but no one admits it). How much minimum do you need to take so that there is a high probability of at least one experienced comrade in the group? In this case population- 100, sample - 10, sample requirements - at least one who has already been to E3. Wikipedia has a less funny, but more practical example about defective parts in a batch. Just like the binomial, the Poisson distribution is a count distribution: the number of times something will happen. It is parameterized not by the probability p and the number of trials n, but by the average intensity λ, which, in analogy with the binomial, is simply a constant value np. Poisson distribution - what it's all about necessary remember when we are talking about counting events over a certain time at a constant given intensity. When there is something, such as packets arriving at a router, or customers appearing in a store, or something waiting in line, think “Poisson”. If the binomial distribution is “how many successes,” then the geometric distribution is “How many failures before success?” The negative binomial distribution is a simple generalization of the previous one. This is the number of failures before there are r, not 1, successes. Therefore, it is further parameterized by this r. It is sometimes described as the number of successes to r failures. But as my life coach says: “You decide what is success and what is failure,” so it’s the same thing, as long as you remember that the probability p should also be the correct probability of success or failure, respectively. If you need a joke to relieve tension, you can mention that the binomial and hypergeometric distributions are an obvious pair, but the geometric and negative binomial are also quite similar, and then say, “Well, who calls them all that, huh?” Well, as before, we move to the limit in the geometric distribution, regarding time shares - and voila. We obtain an exponential distribution that accurately describes the time before the call. This is a continuous distribution, the first of our kind, because the outcome is not necessarily in whole seconds. Like the Poisson distribution, it is parameterized by the intensity λ. Reiterating the connection between the binomial and the geometric, Poisson's “how many events in time?” is related to the exponential “how long until the event?” If there are events whose number per unit time obeys the Poisson distribution, then the time between them obeys the exponential distribution with the same parameter λ. This correspondence between the two distributions must be noted when either of them is discussed. The exponential distribution should come to mind when thinking about "time to event", perhaps "time to failure". In fact, this is such an important situation that more generalized distributions exist to describe MTBF, such as the Weibull distribution. While the exponential distribution is appropriate when the wear rate, or failure rate, for example, is constant, the Weibull distribution can model failure rates increasing (or decreasing) over time. Exponential is, in general, a special case. Think "Weibull" when talking about MTBF. Note translation I was surprised that the author does not write about the need for a comparable scale of summed distributions: if one significantly dominates the others, convergence will be extremely bad. And, in general, absolute mutual independence is not necessary; weak dependence is sufficient. Well, probably good for parties, as he wrote. In its context, normal is associated with all distributions. Although, basically, it is associated with the distribution of all sorts of amounts. The sum of Bernoulli trials follows a binomial distribution and, as the number of trials increases, this binomial distribution becomes closer to a normal distribution. Likewise, its cousin is the hypergeometric distribution. The Poisson distribution - the limiting form of the binomial - also approaches normal with increasing intensity parameter. Outcomes that follow a lognormal distribution produce values whose logarithm is normally distributed. Or in other words: the exponent of a normally distributed value is lognormally distributed. If the sums are normally distributed, then remember that the products are lognormally distributed. The Student's t-distribution is the basis of the t-test, which many non-statisticians study in other fields. It is used to make assumptions about the mean of a normal distribution and also tends to the normal distribution as its parameter increases. Distinctive feature t-distribution - its tails, which are thicker than those of the normal distribution. If the fat-tailed joke didn't rock your neighbor enough, move on to a rather funny tale about beer. More than 100 years ago, Guinness used statistics to improve its stout. Then William Seely Gosset invented a completely new statistical theory for improved barley cultivation. Gossett convinced his boss that other brewers would not understand how to use his ideas, and received permission to publish, but under the pseudonym "Student". The most famous achievement Gosset - this is precisely the t-distribution, which, one might say, is named after him. Finally, the chi-square distribution is the distribution of sums of squares of normally distributed values. The chi-square test is based on this distribution, which itself is based on the sum of squares of the differences, which should be normally distributed. Don't talk about these conjugate distributions, but if you have to, don't forget to talk about the beta distribution, because it is the conjugate prior to most of the distributions mentioned here. Data scientists are sure that this is exactly what it was made for. Mention this casually and go to the door.


Basic concepts of the theory
- sigma algebra of subsets called (random) events;
- probability measure or probability, i.e. sigma-additive finite measure such that .


Probability of a normally distributed random variable falling into a given interval


Bernoulli and uniform
You have already encountered the Bernoulli distribution above, with two outcomes - heads or tails. Imagine it now as a distribution over 0 and 1, 0 is heads, 1 is tails. As is already clear, both outcomes are equally likely, and this is reflected in the diagram. The Bernoulli PDF contains two lines of equal height, representing 2 equally probable outcomes: 0 and 1, respectively. Binomial and hypergeometric
The binomial distribution can be thought of as the sum of the outcomes of those things that follow the Bernoulli distribution. Poisson
What about the number of customers calling hotline to technical support every minute? This is an outcome whose distribution appears to be binomial, if we count each second as a Bernoulli test during which the customer either does not call (0) or calls (1). But power supply organizations know very well: when the electricity is turned off, two people can call in a second. or even more than a hundred of people. Thinking of it as 60,000 millisecond tests doesn't help either - there are more tests, the probability of a call per millisecond is less, even if you don't count two or more at the same time, but, technically, this is still not a Bernoulli test. However, it works logical reasoning with the transition to infinity. Let n tend to infinity and p to 0, so that np is constant. It's like dividing into smaller and smaller fractions of time with an increasingly smaller probability of a call. In the limit we get the Poisson distribution. Geometric and negative binomial
From simple Bernoulli tests a different distribution emerges. How many times will a coin land heads before it lands on heads? The number of tails follows a geometric distribution. Like the Bernoulli distribution, it is parameterized by the probability of a successful outcome, p. It is not parameterized by the number n, the number of throw-tests, because the number of unsuccessful tests is precisely the outcome. Exponential and Weibula
Again about calls to technical support: how long will it take until the next call? The distribution of this waiting time seems to be geometric, because every second until no one calls is like a failure, until the second until the call finally occurs. The number of failures is like the number of seconds until no one called, and this practically time until the next call, but “practically” is not enough for us. The point is that this time will be the sum of whole seconds, and thus it will not be possible to count the wait within this second before the call itself. Normal, lognormal, Student's t and chi-square
The normal, or Gaussian, distribution is probably one of the most important. Its bell-shaped shape is immediately recognizable. Like , this is a particularly curious entity that manifests itself everywhere, even from the most seemingly simple sources. Take a set of values that follow the same distribution - any one! - and fold them. The distribution of their sum follows (approximately) a normal distribution. The more things are added up, the closer their sum corresponds to the normal distribution (the catch: the distribution of terms must be predictable, independent, it tends only to normal). That this is true despite the original distribution is amazing.
This is called the “central limit theorem”, and you need to know what it is, why it is called that and what it means, otherwise you will instantly laugh. Gamma and beta
At this point, if you have already started talking about something chi-square, the conversation begins in earnest. You may already be talking to real statisticians, and you should probably bow out already, because things like the gamma distribution may come up. This is a generalization And exponential And chi-square distribution. Like the exponential distribution, it is used for complex models waiting times. For example, a gamma distribution appears when the time to the next n events is simulated. It appears in machine learning as the “adjoint prior distribution” to a couple of other distributions. The beginning of wisdom
Probability distributions are something you can't know too much about. The truly interested can refer to this super-detailed map of all probability distributions Add tags







")

