DNA and genes. Complementarity of nucleotide chains in the DNA double helix
Solution principles typical tasks in molecular biology
Problem 1
One of the chains of the DNA molecule has the following order of nucleotides: ACG TAG CTA HCG... Write the order of nucleotides in the complementary DNA chain.
Explanation of the solution to the problem. It is known that two chains in a DNA molecule are connected by hydrogen bonds between complementary nucleotides (A-T, G-C). The order of nucleotides in a known DNA chain is:
A C G T A G C T A G C G
T G C A T C G A T C G C is the order of nucleotides in the complementary DNA chain.
Answer: the order of nucleotides in the complementary strand of DNA: TGCATCGATTCGC
Problem 2
The order of nucleotides in one of the chains of the DNA molecule is as follows: AGCTACGTACA... Determine the order of amino acids in the polypeptide encoded by this genetic information.
Explanation of the solution to the problem. It is known that the matrix for the synthesis of a polypeptide is an mRNA molecule, the matrix for the synthesis of which, in turn, is one of the chains of the DNA molecule. The first stage of protein biosynthesis: transcription - rewriting the order of nucleotides from a DNA chain to mRNA. The synthesis of mRNA occurs according to the principle of complementarity (A-U, G-C). Instead of thymine in mRNA, the nitrogenous base is uracil. Known DNA strand:
A G C T A C G T A C G A...
U C G A U G C A U G C U... is the order of nucleotides in i-RNA.
One amino acid is encoded by three adjacent nucleotides of the i-RNA chain (codons) - we break the i-RNA into codons:
UCG, AUG, CAU, HCU and using the codon table we find the amino acids corresponding to them: UCG corresponds to serine, AUG to methionine, CAC to hiscidine, HCU to alanine.
Answer: the order of amino acids in the encoded polypeptide: ser - met - gis - ala ...
Problem 3
One of the chains of the DNA molecule has the following nucleotide order: GGCATGGATCAT...
a) Determine the amino acid sequence in the corresponding polypeptide if it is known that RNA is also synthesized on a complementary DNA strand.
b) How will the primary structure of the polypeptide change if the third nucleotide is lost?
Explanation of the solution to the problem.
a) It is known that the mRNA molecule is synthesized according to the principle of complementarity on one of the chains of the DNA molecule. We know the order of nucleotides in one DNA strand and are told that mRNA is synthesized on a complementary strand. Therefore, it is necessary to build a complementary DNA strand, remembering that adenine corresponds to thymine, and guanine to cytosine. The double strand of DNA will look like this:
G G C A T G G A T C A T…
C C G T A C C T A G T A ...
Now you can build a molecule and - RNA. It should be remembered that instead of thymine, the RNA molecule contains uracil. Hence:
DNA: C C G T A C C T A G A T...
I-RNA: G G C A U G G A U C A U….
Three adjacent nucleotides (triplet, codon) of mRNA determine the addition of one amino acid. We find the amino acids corresponding to triplets using the codon table. Codon GHC corresponds to gly, A UG – met, GAU – asp, CAU – gis. Therefore, the sequence of amino acids of a section of the polypeptide chain will be: gly - met - asp - gis ...
b) If the third nucleotide falls out in the chain of a DNA molecule, it will look like this:
GGATGGATTSAT…
Complementary chain: CCTACCTAGTA...
Information i-RNA: GGAUGGAUCA...
All codons will change. The first codon GGA corresponds to the amino acid gly, the second UUG corresponds to three, the third AUC corresponds to ile, and the fourth is incomplete. Thus, the polypeptide section will look like:
Gly - three - ile..., i.e. there will be a significant change in the order and number of amino acids in the polypeptide.
Answer: a) sequence of amino acids in the polypeptide: gly – met – asp – gis...,
b) after the loss of the third nucleotide, the sequence of amino acids in the polypeptide is: gly - three - ile...
Problem 4
The polypeptide has the following order of amino acids: fen - tre - ala - ser - arg...
a) Determine one of the variants of the nucleotide sequence of the gene encoding this polypeptide.
b) Which tRNAs (with which anticodons) are involved in the synthesis of this protein? Write one of the possible options.
Explanation of the solution to the problem.
a) The polypeptide has the following sequence of amino acids: fen - tre - ala - ser - arg... Using the codon table, we find one of the triplets that encodes the corresponding amino acids. Fen - UUU, tre - ATSU, ala - GCU, ser - AGU, arg - AGA. Therefore, the mRNA encoding this polypeptide will have the following nucleotide sequence:
UUUATSUGTSUAGUAGA...
The order of nucleotides in the coding strand of DNA is: AATGATCGATCATCT...
Complementary DNA strand: TTTACTGCTAGTAGA...
b) Using the codon table, we find one of the variants of the mRNA nucleotide sequence (as in the previous version). T-RNA anticodons are complementary to i-RNA codons:
i-RNA UUUATSUGTSUAGUAGA...
tRNA anticodons AAA, UGA, CGA, UCA, UCU
Answer: a) one of the variants of the nucleotide sequence in the gene will be:
AAATGATSGATTSATTST
TTTATCTTGCTAGTAGA,
b) t-RNAs with anticodons (one of the options): AAA, UGA, CGA, UCA, UCU will participate in the synthesis of this protein.
Self-control tasks
1. One of the chains of a DNA molecule fragment has the following nucleotide sequence: AGTGATGTTGGTGTA... What will be the structure of the second chain of the DNA molecule?
2. A section of one DNA strand has the following sequence of nucleotides: TGAACACTAGTTTAGAATACCA... What is the sequence of amino acids in the polypeptide corresponding to this genetic information?
3. A section of one DNA strand has the following structure: TATTTCTTTTTTGT... Indicate the structure of the corresponding part of the protein molecule synthesized with the participation of the complementary chain. How will the primary structure of a protein fragment change if the second nucleotide from the beginning is lost?
4. Part of a protein molecule has the following sequence of amino acids: ser - ala - tyr - lei - asp... Which tRNAs (with which anticodons) are involved in the synthesis of this protein? Write one of the possible options.
5. Write one of the variants of the nucleotide sequence in the gene if the encoded protein has the following primary structure:
Ala - tre - liz - asn - ser - gln - glu - asp ...
On the right is the largest helix of human DNA, built from people on the beach in Varna (Bulgaria), included in the Guinness Book of Records on April 23, 2016
Deoxyribonucleic acid. General information
DNA (deoxyribonucleic acid) is a kind of blueprint for life, a complex code that contains data on hereditary information. This complex macromolecule is capable of storing and transmitting hereditary genetic information from generation to generation. DNA determines such properties of any living organism as heredity and variability. The information encoded in it sets the entire development program of any living organism. Genetically determined factors predetermine the entire course of life of both a person and any other organism. Artificial or natural influences of the external environment can only slightly affect the overall expression of individual genetic traits or affect the development of programmed processes.
Deoxyribonucleic acid(DNA) is a macromolecule (one of the three main ones, the other two are RNA and proteins) that ensures storage, transmission from generation to generation and implementation of the genetic program for the development and functioning of living organisms. DNA contains structural information various types RNA and proteins.
In eukaryotic cells (animals, plants and fungi), DNA is found in the cell nucleus as part of chromosomes, as well as in some cellular organelles (mitochondria and plastids). In the cells of prokaryotic organisms (bacteria and archaea), a circular or linear DNA molecule, the so-called nucleoid, is attached from the inside to the cell membrane. In them and in lower eukaryotes (for example, yeast), small autonomous, predominantly circular DNA molecules called plasmids are also found.
From a chemical point of view, DNA is a long polymer molecule consisting of repeating blocks called nucleotides. Each nucleotide consists of a nitrogenous base, a sugar (deoxyribose) and a phosphate group. The bonds between nucleotides in the chain are formed due to deoxyribose ( WITH) and phosphate ( F) groups (phosphodiester bonds).

Rice. 2. The nucleotide consists of a nitrogenous base, a sugar (deoxyribose) and a phosphate group
In the vast majority of cases (except for some viruses containing single-stranded DNA), the DNA macromolecule consists of two chains oriented with nitrogenous bases towards each other. This double-stranded molecule is twisted along a helix.
There are four types of nitrogenous bases found in DNA (adenine, guanine, thymine and cytosine). The nitrogenous bases of one of the chains are connected to the nitrogenous bases of the other chain by hydrogen bonds according to the principle of complementarity: adenine combines only with thymine ( A-T), guanine - only with cytosine ( G-C). It is these pairs that make up the “rungs” of the DNA spiral “staircase” (see: Fig. 2, 3 and 4).

Rice. 2. Nitrogenous bases
The nucleotide sequence allows you to “encode” information about various types RNA, the most important of which are messenger RNA (mRNA), ribosomal RNA (rRNA) and transport RNA (tRNA). All these types of RNA are synthesized on a DNA template by copying a DNA sequence into an RNA sequence synthesized during transcription, and take part in protein biosynthesis (the translation process). In addition to coding sequences, cell DNA contains sequences that perform regulatory and structural functions.

Rice. 3. DNA replication
Location of basic combinations chemical compounds DNA and the quantitative relationships between these combinations provide the coding of hereditary information.
Education new DNA (replication)
- Replication process: unwinding of the DNA double helix - synthesis of complementary strands by DNA polymerase - formation of two DNA molecules from one.
- The double helix "unzips" into two branches when enzymes break the bond between the base pairs of chemical compounds.
- Each branch is an element of new DNA. New base pairs are connected in the same sequence as in the parent branch.
Upon completion of duplication, two independent helices are formed, created from chemical compounds of the parent DNA and having the same genetic code. In this way, DNA is able to pass information from cell to cell.
More details:
STRUCTURE OF NUCLEIC ACIDS

Rice. 4. Nitrogen bases: adenine, guanine, cytosine, thymine
Deoxyribonucleic acid(DNA) refers to nucleic acids. Nucleic acids are a class of irregular biopolymers whose monomers are nucleotides.
Nucleotides consist of nitrogenous base, connected to a five-carbon carbohydrate (pentose) - deoxyribose(in case of DNA) or ribose(in the case of RNA), which combines with a phosphoric acid residue (H 2 PO 3 -).
Nitrogenous bases There are two types: pyrimidine bases - uracil (only in RNA), cytosine and thymine, purine bases - adenine and guanine.

Rice. 5. Types of nitrogenous bases: pyrimidine and purine
The carbon atoms in the pentose molecule are numbered from 1 to 5. The phosphate combines with the third and fifth carbon atoms. This is how nucleinotides are combined into a nucleic acid chain. Thus, we can distinguish the 3' and 5' ends of the DNA strand:

Rice. 6. Isolation highlight the 3’ and 5’ ends of the DNA chain
Two strands of DNA form double helix. These chains in the spiral are oriented in opposite directions. In different strands of DNA, nitrogenous bases are connected to each other by hydrogen bonds. Adenine always pairs with thymine, and cytosine always pairs with guanine. It's called complementarity rule.
Complementarity rule:
| A-T G-C |
For example, if we are given a DNA strand with the sequence
3’- ATGTCCTAGCTGCTCG - 5’,
then the second chain will be complementary to it and directed in the opposite direction - from the 5’ end to the 3’ end:
5'- TACAGGATCGACGAGC- 3'.

Rice. 7. Direction of the chains of the DNA molecule and the connection of nitrogenous bases using hydrogen bonds
REPLICATION
DNA replication is the process of doubling a DNA molecule through template synthesis. Replication occurs by semi-conservative mechanism. This means that the double helix of DNA unwinds and a new chain is built on each of its chains according to the principle of complementarity. The daughter DNA molecule thus contains one strand from the parent molecule and one newly synthesized one. Replication occurs in the direction from the 3' to the 5' end of the mother strand.

Rice. 8. Replication (doubling) of a DNA molecule
DNA synthesis- this is not as complicated a process as it might seem at first glance. If you think about it, first you need to figure out what synthesis is. This is the process of combining something into one whole. The formation of a new DNA molecule occurs in several stages:
- DNA topoisomerase, located in front of the replication fork, cuts the DNA in order to facilitate its unwinding and unwinding.
- DNA helicase, following topoisomerase, influences the process of “unwinding” of the DNA helix.
- DNA binding proteins bind DNA strands and also stabilize them, preventing them from sticking to each other.
- DNA polymerase synthesizes the leading strand of daughter DNA.

Rice. 9. Schematic representation of the replication process, numbers indicate: (1) Lagging strand, (2) Leading strand, (3) DNA polymerase (Polα), (4) DNA ligase, (5) RNA primer, (6) Primase , (7) Okazaki fragment, (8) DNA polymerase (Polδ), (9) Helicase, (10) Single-stranded DNA binding proteins, (11) Topoisomerase
RNA structure
Ribonucleic acid(RNA) is one of the three main macromolecules (the other two are DNA and proteins) that are found in the cells of all living organisms.
Just like DNA, RNA consists of a long chain, in which each link is called a nucleotide. Each nucleotide consists of a nitrogenous base, a ribose sugar, and a phosphate group. However, unlike DNA, RNA usually has one strand rather than two. The pentose in RNA is ribose, not deoxyribose (ribose has an additional hydroxyl group on the second carbohydrate atom). Finally, DNA differs from RNA in the composition of nitrogenous bases: instead of thymine ( T) RNA contains uracil ( U) , which is also complementary to adenine.
The sequence of nucleotides allows RNA to encode genetic information. All cellular organisms use RNA (mRNA) to program protein synthesis.
Cellular RNA is produced through a process called transcription , that is, the synthesis of RNA on a DNA matrix, carried out by special enzymes - RNA polymerases.
Messenger RNAs (mRNAs) then take part in a process called broadcast, those. protein synthesis on an mRNA matrix with the participation of ribosomes. Other RNAs undergo chemical modifications after transcription, and after the formation of secondary and tertiary structures, they perform functions depending on the type of RNA.

Rice. 10. The difference between DNA and RNA in the nitrogenous base: instead of thymine (T), RNA contains uracil (U), which is also complementary to adenine.
TRANSCRIPTION
This is the process of RNA synthesis on a DNA template. DNA unwinds at one of the sites. One of the strands contains information that needs to be copied onto an RNA molecule - this strand is called the coding strand. The second strand of DNA, complementary to the coding one, is called the template. During transcription, a complementary RNA chain is synthesized on the template strand in the 3’ - 5’ direction (along the DNA strand). This creates an RNA copy of the coding strand.
![]()
Rice. 11. Schematic representation of the transcription
For example, if we are given the sequence of the coding chain
3’- ATGTCCTAGCTGCTCG - 5’,
then, according to the complementarity rule, the matrix chain will carry the sequence
5’- TACAGGATCGACGAGC- 3’,
and the RNA synthesized from it is the sequence
BROADCAST
Let's consider the mechanism protein synthesis on the RNA matrix, as well as the genetic code and its properties. Also, for clarity, at the link below, we recommend watching a short video about the processes of transcription and translation occurring in a living cell:

Rice. 12. Protein synthesis process: DNA codes for RNA, RNA codes for protein
GENETIC CODE
Genetic code- a method of encoding the amino acid sequence of proteins using a sequence of nucleotides. Each amino acid is encoded by a sequence of three nucleotides - a codon or triplet.
Genetic code common to most pro- and eukaryotes. The table shows all 64 codons and the corresponding amino acids. The base order is from the 5" to the 3" end of the mRNA.
Table 1. Standard genetic code
|
1st tion |
2nd base |
3rd tion |
|||||||
|
U |
C |
A |
G |
||||||
|
U |
U U U |
(Phe/F) |
U C U |
(Ser/S) |
U A U |
(Tyr/Y) |
U G U |
(Cys/C) |
U |
|
U U C |
U C C |
U A C |
U G C |
C |
|||||
|
U U A |
(Leu/L) |
U C A |
U A A |
Stop codon** |
U G A |
Stop codon** |
A |
||
|
U U G |
U C G |
U A G |
Stop codon** |
U G G |
(Trp/W) |
G |
|||
|
C |
C U U |
C C U |
(Pro/P) |
C A U |
(His/H) |
C G U |
(Arg/R) |
U |
|
|
C U C |
C C C |
C A C |
C G C |
C |
|||||
|
C U A |
C C A |
C A A |
(Gln/Q) |
C GA |
A |
||||
|
C U G |
C C G |
C A G |
C G G |
G |
|||||
|
A |
A U U |
(Ile/I) |
A C U |
(Thr/T) |
A A U |
(Asn/N) |
A G U |
(Ser/S) |
U |
|
A U C |
A C C |
A A C |
A G C |
C |
|||||
|
A U A |
A C A |
A A A |
(Lys/K) |
A G A |
A |
||||
|
A U G |
(Met/M) |
A C G |
A A G |
A G G |
G |
||||
|
G |
G U U |
(Val/V) |
G C U |
(Ala/A) |
G A U |
(Asp/D) |
G G U |
(Gly/G) |
U |
|
G U C |
G C C |
G A C |
G G C |
C |
|||||
|
G U A |
G C A |
G A A |
(Glu/E) |
G G A |
A |
||||
|
G U G |
G C G |
G A G |
G G G |
G |
|||||
Among the triplets, there are 4 special sequences that serve as “punctuation marks”:
- *Triplet AUG, also encoding methionine, is called start codon. The synthesis of a protein molecule begins with this codon. Thus, during protein synthesis, the first amino acid in the sequence will always be methionine.
- **Triplets UAA, UAG And U.G.A. are called stop codons and do not code for a single amino acid. At these sequences, protein synthesis stops.
Properties of the genetic code
1. Triplety. Each amino acid is encoded by a sequence of three nucleotides - a triplet or codon.
2. Continuity. There are no additional nucleotides between the triplets; the information is read continuously.
3. Non-overlapping. One nucleotide cannot be included in two triplets at the same time.
4. Unambiguity. One codon can code for only one amino acid.

5. Degeneracy. One amino acid can be encoded by several different codons.

6. Versatility. The genetic code is the same for all living organisms.
Example. We are given the sequence of the coding chain:
3’- CCGATTGCACGTCGATCGTATA- 5’.
The matrix chain will have the sequence:
5’- GGCTAACGTGCAGCTAGCATAT- 3’.
Now we “synthesize” information RNA from this chain:
3’- CCGAUUGCACGUCGAUCGUAUA- 5’.
Protein synthesis proceeds in the direction 5’ → 3’, therefore, we need to reverse the sequence to “read” the genetic code:
5’- AUAUGCUAGCUGCACGUUAGCC- 3’.
Now let's find the start codon AUG:
5’- AU AUG CUAGCUGCACGUUAGCC- 3’.
Let's divide the sequence into triplets:
sounds like this: information is transferred from DNA to RNA (transcription), from RNA to protein (translation). DNA can also be duplicated by replication, and the process of reverse transcription is also possible, when DNA is synthesized from an RNA template, but this process is mainly characteristic of viruses.

Rice. 13. Central Dogma of Molecular Biology
GENOME: GENES and CHROMOSOMES
(general concepts)
Genome - the totality of all the genes of an organism; its complete chromosome set.
The term “genome” was proposed by G. Winkler in 1920 to describe the set of genes contained in the haploid set of chromosomes of organisms of the same biological species. The original meaning of this term indicated that the concept of genome, in contrast to genotype, is genetic characteristics the species as a whole, rather than an individual. With the development of molecular genetics, the meaning of this term has changed. It is known that DNA, which is the carrier of genetic information in most organisms and, therefore, forms the basis of the genome, includes not only genes in modern sense this word. Most of the DNA of eukaryotic cells is represented by non-coding (“redundant”) nucleotide sequences that do not contain information about proteins and nucleic acids. Thus, the main part of the genome of any organism is the entire DNA of its haploid set of chromosomes.
Genes are sections of DNA molecules that encode polypeptides and RNA molecules
Over the last century, our understanding of genes has changed significantly. Previously, a genome was a region of a chromosome that encodes or defines one characteristic or phenotypic(visible) property, such as eye color.
In 1940, George Beadle and Edward Tatham proposed a molecular definition of the gene. Scientists processed fungal spores Neurospora crassa X-rays and other agents causing change in the DNA sequence ( mutations), and discovered mutant strains of the fungus that had lost some specific enzymes, which in some cases led to disruption of the entire metabolic pathway. Beadle and Tatem concluded that a gene is a piece of genetic material that specifies or codes for a single enzyme. This is how the hypothesis appeared "one gene - one enzyme". This concept was later expanded to define "one gene - one polypeptide", since many genes encode proteins that are not enzymes, and the polypeptide may be a subunit of a complex protein complex.
In Fig. Figure 14 shows a diagram of how triplets of nucleotides in DNA determine a polypeptide - the amino acid sequence of a protein through the mediation of mRNA. One of the DNA chains plays the role of a template for the synthesis of mRNA, the nucleotide triplets (codons) of which are complementary to the DNA triplets. In some bacteria and many eukaryotes, coding sequences are interrupted by non-coding regions (called introns).
Modern biochemical determination of the gene even more specific. Genes are all sections of DNA that encode the primary sequence final products, which include polypeptides or RNA that have a structural or catalytic function.
Along with genes, DNA also contains other sequences that perform exclusively a regulatory function. Regulatory sequences may mark the beginning or end of genes, influence transcription, or indicate the site of initiation of replication or recombination. Some genes can be expressed in different ways, with the same DNA region serving as a template for the formation of different products.
We can roughly calculate minimum size gene, encoding the middle protein. Each amino acid in a polypeptide chain is encoded by a sequence of three nucleotides; the sequences of these triplets (codons) correspond to the chain of amino acids in the polypeptide that is encoded by this gene. Polypeptide chain of 350 amino acid residues (chain medium length) corresponds to a sequence of 1050 bp. ( base pairs). However, many eukaryotic genes and some prokaryotic genes are interrupted by DNA segments that do not carry protein information, and therefore turn out to be much longer than a simple calculation shows.
How many genes are on one chromosome?
 Rice. 15. View of chromosomes in prokaryotic (left) and eukaryotic cells. Histones are a large class of nuclear proteins that perform two main functions: they participate in the packaging of DNA strands in the nucleus and in the epigenetic regulation of nuclear processes such as transcription, replication and repair.
Rice. 15. View of chromosomes in prokaryotic (left) and eukaryotic cells. Histones are a large class of nuclear proteins that perform two main functions: they participate in the packaging of DNA strands in the nucleus and in the epigenetic regulation of nuclear processes such as transcription, replication and repair.
As is known, bacterial cells have a chromosome in the form of a DNA strand arranged in a compact structure - a nucleoid. Prokaryotic chromosome Escherichia coli, whose genome has been completely deciphered, is a circular DNA molecule (in fact, it is not a perfect circle, but rather a loop without a beginning or end), consisting of 4,639,675 bp. This sequence contains approximately 4,300 protein genes and another 157 genes for stable RNA molecules. IN human genome approximately 3.1 billion base pairs corresponding to almost 29,000 genes located on 24 different chromosomes.
Prokaryotes (Bacteria).
 Bacterium E. coli has one double-stranded circular DNA molecule. It consists of 4,639,675 bp. and reaches a length of approximately 1.7 mm, which exceeds the length of the cell itself E. coli approximately 850 times. In addition to the large circular chromosome as part of the nucleoid, many bacteria contain one or several small circular DNA molecules that are freely located in the cytosol. These extrachromosomal elements are called plasmids(Fig. 16).
Bacterium E. coli has one double-stranded circular DNA molecule. It consists of 4,639,675 bp. and reaches a length of approximately 1.7 mm, which exceeds the length of the cell itself E. coli approximately 850 times. In addition to the large circular chromosome as part of the nucleoid, many bacteria contain one or several small circular DNA molecules that are freely located in the cytosol. These extrachromosomal elements are called plasmids(Fig. 16).
Most plasmids consist of only a few thousand base pairs, some contain more than 10,000 bp. They carry genetic information and replicate to form daughter plasmids, which enter the daughter cells during the division of the parent cell. Plasmids are found not only in bacteria, but also in yeast and other fungi. In many cases, plasmids provide no benefit to the host cells and their sole purpose is to reproduce independently. However, some plasmids carry genes beneficial to the host. For example, genes contained in plasmids can make bacterial cells resistant to antibacterial agents. Plasmids carrying the β-lactamase gene provide resistance to β-lactam antibiotics such as penicillin and amoxicillin. Plasmids can pass from cells that are resistant to antibiotics to other cells of the same or a different species of bacteria, causing those cells to also become resistant. Intensive use of antibiotics is a powerful selective factor that promotes the spread of plasmids encoding antibiotic resistance (as well as transposons that encode similar genes) among pathogenic bacteria, leading to the emergence of bacterial strains with resistance to multiple antibiotics. Doctors are beginning to understand the dangers of widespread use of antibiotics and prescribe them only in cases of urgent need. For similar reasons, the widespread use of antibiotics to treat farm animals is limited.
See also: Ravin N.V., Shestakov S.V. Genome of prokaryotes // Vavilov Journal of Genetics and Breeding, 2013. T. 17. No. 4/2. pp. 972-984.
Eukaryotes.
Table 2. DNA, genes and chromosomes of some organisms
|
Shared DNA p.n. |
Number of chromosomes* |
Approximate number of genes |
|
|
Escherichia coli(bacterium) |
4 639 675 |
4 435 |
|
|
Saccharomyces cerevisiae(yeast) |
12 080 000 |
16** |
5 860 |
|
Caenorhabditis elegans(nematode) |
90 269 800 |
12*** |
23 000 |
|
Arabidopsis thaliana(plant) |
119 186 200 |
33 000 |
|
|
Drosophila melanogaster(fruit fly) |
120 367 260 |
20 000 |
|
|
Oryza sativa(rice) |
480 000 000 |
57 000 |
|
|
Mus musculus(mouse) |
2 634 266 500 |
27 000 |
|
|
Homo sapiens(Human) |
3 070 128 600 |
29 000 |
Note. Information is constantly updated; For more up-to-date information, please refer to individual genomics project websites
* For all eukaryotes, except yeast, the diploid set of chromosomes is given. Diploid kit chromosomes (from the Greek diploos - double and eidos - species) - a double set of chromosomes (2n), each of which has a homologous one.
**Haploid set. Wild yeast strains typically have eight (octaploid) or more sets of these chromosomes.
***For females with two X chromosomes. Males have an X chromosome, but no Y, i.e. only 11 chromosomes.
Yeast, one of the smallest eukaryotes, has 2.6 times more DNA than E. coli(Table 2). Fruit fly cells Drosophila, classical object genetic research, contain 35 times more DNA, and human cells contain about 700 times more DNA than human cells E. coli. Many plants and amphibians contain even more DNA. The genetic material of eukaryotic cells is organized in the form of chromosomes. Diploid set of chromosomes (2 n) depends on the type of organism (Table 2).
For example, a human somatic cell has 46 chromosomes ( rice. 17). Each chromosome of a eukaryotic cell, as shown in Fig. 17, A, contains one very large double-stranded DNA molecule. Twenty-four human chromosomes (22 paired chromosomes and two sex chromosomes X and Y) vary in length by more than 25 times. Each eukaryotic chromosome contains a specific set of genes.

Rice. 17. Chromosomes of eukaryotes.A- a pair of linked and condensed sister chromatids from the human chromosome. In this form, eukaryotic chromosomes remain after replication and in metaphase during mitosis. b- a complete set of chromosomes from a leukocyte of one of the authors of the book. Each normal human somatic cell contains 46 chromosomes.
If you connect the DNA molecules of the human genome (22 chromosomes and chromosomes X and Y or X and X), you get a sequence about one meter long. Note: In all mammals and other heterogametic male organisms, females have two X chromosomes (XX) and males have one X chromosome and one Y chromosome (XY).
Most human cells, so the total DNA length of such cells is about 2 m. An adult human has approximately 10 14 cells, so the total length of all DNA molecules is 2・10 11 km. For comparison, the circumference of the Earth is 4・10 4 km, and the distance from the Earth to the Sun is 1.5・10 8 km. This is how amazingly compact the DNA is packed in our cells!
In eukaryotic cells there are other organelles containing DNA - mitochondria and chloroplasts. Many hypotheses have been put forward regarding the origin of mitochondrial and chloroplast DNA. The generally accepted point of view today is that they represent the rudiments of the chromosomes of ancient bacteria, which penetrated the cytoplasm of the host cells and became the precursors of these organelles. Mitochondrial DNA encodes mitochondrial tRNAs and rRNAs, as well as several mitochondrial proteins. More than 95% of mitochondrial proteins are encoded by nuclear DNA.
STRUCTURE OF GENES
Let's consider the structure of the gene in prokaryotes and eukaryotes, their similarities and differences. Despite the fact that a gene is a section of DNA that encodes only one protein or RNA, in addition to the immediate coding part, it also includes regulatory and other structural elements, having different structures in prokaryotes and eukaryotes.
Coding sequence- the main structural and functional unit of the gene, it is in it that the triplets of nucleotides encoding are locatedamino acid sequence. It begins with a start codon and ends with a stop codon.
Before and after the coding sequence there are untranslated 5' and 3' sequences. They perform regulatory and auxiliary functions, for example, ensuring the landing of the ribosome on mRNA.
Untranslated and coding sequences make up the transcription unit - the transcribed section of DNA, that is, the section of DNA from which mRNA synthesis occurs.
Terminator- a non-transcribed section of DNA at the end of a gene where RNA synthesis stops.
At the beginning of the gene is regulatory region, which includes promoter And operator.
Promoter- the sequence to which the polymerase binds during transcription initiation. Operator- this is an area that special proteins can bind to - repressors, which can reduce the activity of RNA synthesis from this gene - in other words, reduce it expression.
Gene structure in prokaryotes
The general plan of gene structure in prokaryotes and eukaryotes is no different - both contain a regulatory region with a promoter and operator, a transcription unit with coding and untranslated sequences, and a terminator. However, the organization of genes in prokaryotes and eukaryotes is different.

Rice. 18. Scheme of gene structure in prokaryotes (bacteria) -the image is enlarged
At the beginning and end of the operon there are common regulatory regions for several structural genes. One mRNA molecule is read from the transcribed region of the operon, which contains several coding sequences, each of which has its own start and stop codon. From each of these areas withone protein is synthesized. Thus, Several protein molecules are synthesized from one mRNA molecule.
Prokaryotes are characterized by the combination of several genes into a single functional unit - operon. The operation of the operon can be regulated by other genes, which can be noticeably distant from the operon itself - regulators. The protein translated from this gene is called repressor. It binds to the operator of the operon, regulating the expression of all genes contained in it at once.
Prokaryotes are also characterized by the phenomenon Transcription-translation interfaces.
![]()
Rice. 19 The phenomenon of coupling of transcription and translation in prokaryotes - the image is enlarged
In prokaryotes. Complementary DNA also formed by retroviruses (HIV-1, HIV-2, Simian immunodeficiency virus) and then integrated into the host DNA, forming a provirus.
Eukaryotic genes can often be expressed in prokaryotic cells. In the simplest case, the method involves inserting eukaryotic DNA into the prokaryotic genome, then transcribing the DNA into mRNA and then translating the mRNA into proteins. Prokaryotic cells do not have enzymes to excise introns, and therefore introns from eukaryotic DNA must be excised before being inserted into the prokaryotic genome. DNA complementary to mature mRNA is thus called complementary DNA - cDNA(cDNA). Successful expression of proteins encoded in eukaryotic cDNA in prokaryotes also requires prokaryotic gene regulatory elements (e.g., promoters).
One of the methods for obtaining the necessary gene (DNA molecule), which will be subject to replication (cloning) with the release of a significant number of replicas, is the construction of complementary DNA (cDNA) on mRNA. This method requires the use of reverse transcriptase, an enzyme that is present in some RNA viruses and enables the synthesis of DNA on an RNA template.
The method is widely used to obtain cDNA and involves the isolation from total tissue mRNA of mRNA that encodes the translation of a specific protein (for example, interferon, insulin) with further synthesis on this mRNA as the template of the required cDNA using reverse transcriptase.
The gene that was obtained using the above procedure (cDNA) must be introduced into the bacterial cell in such a way that it is integrated into its genome. To do this, recombinant DNA is formed, which consists of cDNA and a special DNA molecule that acts as a conductor, or vector, capable of penetrating the recipient into the cell. Viruses or plasmids are used as vectors for cDNA. Plasmids are small circular DNA molecules that are located separately from the nucleoid of the bacterial cell, contain several genes important for the function of the entire cell (for example, antibiotic resistance genes and can replicate independently of the main genome (DNA) of the cell. Biologically important and practically The properties of plasmids useful for genetic engineering are their ability to transfer from one cell to another through the mechanism of transformation or conjugation, as well as the ability to be included in the bacterial chromosome and replicate together with it.
Write a review about the article "Complementary DNA"
Notes
|
||||||||||||||||||||||||||||||||||
Excerpt characterizing Complementary DNA
– And these “keys”, are they never repeated by others? – I decided to continue my questions.“No, but sometimes something else happens...” for some reason, the little one answered, smiling funny. “That’s exactly how I got caught at the beginning, for which they even beat me up very badly... Oh, that was so stupid!..”
- How? – I asked, very interested.
Stella immediately answered cheerfully:
- Oh, that was very funny! - and after thinking a little, she added, “but it’s also dangerous... I was looking on all the “floors” for the past incarnation of my grandmother, and instead of her, a completely different entity came along her “thread”, which somehow managed to “copy” my grandmother’s “ flower" (apparently also a "key"!) and, just as I had time to rejoice that I had finally found it, this unfamiliar entity mercilessly hit me in the chest. Yes, so much that my soul almost flew away!..
- How did you get rid of her? – I was surprised.
“Well, to be honest, I didn’t get rid of it...” the girl became embarrassed. - I just called my grandmother...
– What do you call “floors”? – I still couldn’t calm down.
– Well, these are different “worlds” where the essences of the dead live... In the most beautiful and highest live those who were good... and, probably, the strongest too.
- People like you? – I asked, smiling.
- Oh, no, of course! I probably got here by mistake. – The girl said completely sincerely. – Do you know what’s most interesting? From this “floor” we can walk everywhere, but from the others no one can get here... Isn’t that interesting?..
Yes, it was very strange and very excitingly interesting for my “starved” brain, and I really wanted to know more!.. Maybe because until that day no one had ever really explained anything to me, but just sometimes someone -gave (such as my “ star friends"), and therefore, even such a simple childish explanation already made me unusually happy and forced me to delve even more furiously into my experiments, conclusions and mistakes... as usual, finding even more incomprehensible in everything that was happening. My problem was that I could do or create “unusual” very easily, but the whole problem was that I also wanted to understand how I create it all... And this is precisely what I have not been very successful in yet ...
– What about the other “floors”? Do you know how many there are? Are they completely different, unlike this one?.. – unable to stop, I impatiently bombarded Stella with questions.
- Oh, I promise you, we will definitely go there for a walk! You will see how interesting it is there!.. Only there it is also dangerous, especially in one place. There are such monsters walking around there!.. And the people are not very nice either.
“I think I’ve already seen similar monsters,” I said, not very confidently, remembering something. - Look...
And I tried to show her the first astral creatures I met in my life, who attacked baby Vesta’s drunken dad.
- Oh, so these are the same! Where did you see them? On Earth?!..
- Well, yes, they came when I was helping one good little girl say goodbye to her dad...
“So they come to the living too?..” my friend was very surprised.
– I don’t know, Stella. I still know almost nothing at all... And I would really like not to walk in the dark and not learn everything only by “touch”... or from my own experience, when they constantly “hit me on the head” for this... What do you think , your grandmother wouldn’t have taught me something?..
– I don’t know... You should probably ask her about it yourself?
The girl thought deeply about something, then laughed loudly and said cheerfully:
– It was so funny when I just started “creating”!!! Oh, you would know how funny and amusing it was!.. At the beginning, when everyone “left” me, I was very sad, and I cried a lot... I didn’t know where they were, my mother and my brother. .. I didn’t know anything yet. That’s when, apparently, my grandmother felt sorry for me and she began to teach me a little. And... oh, what happened!.. At first I constantly fell through somewhere, created everything “topsy-turvy” and my grandmother had to watch me almost all the time. And then I learned... It’s even a pity, because now she comes less often... and I’m afraid that maybe someday she won’t come at all...
Molecular genetics – a branch of genetics that deals with the study of heredity at the molecular level.
Nucleic acids. DNA replication. Template synthesis reactions
Nucleic acids (DNA, RNA) were discovered in 1868 by the Swiss biochemist I.F. Misher. Nucleic acids are linear biopolymers consisting of monomers - nucleotides.
DNA - structure and functions
The chemical structure of DNA was deciphered in 1953 by the American biochemist J. Watson and the English physicist F. Crick.
General structure of DNA. The DNA molecule consists of 2 chains that are twisted into a spiral (Fig. 11) one around the other and around a common axis. DNA molecules can contain from 200 to 2x10 8 nucleotide pairs. Along the DNA helix, neighboring nucleotides are located at a distance of 0.34 nm from each other. A full turn of the helix includes 10 base pairs. Its length is 3.4 nm.
Rice. 11 . DNA structure diagram (double helix)
Polymerity of the DNA molecule. The DNA molecule - bioploimer consists of complex compounds - nucleotides.
Structure of a DNA nucleotide. A DNA nucleotide consists of 3 units: one of the nitrogenous bases (adenine, guanine, cytosine, thymine); deoxyribose (monosaccharide); phosphoric acid residue (Fig. 12).
There are 2 groups of nitrogenous bases:
purines - adenine (A), guanine (G), containing two benzene rings;
pyrimidine - thymine (T), cytosine (C), containing one benzene ring.
DNA contains the following types of nucleotides: adenine (A); guanine (G); cytosine (C); thymine (T). The names of nucleotides correspond to the names of the nitrogenous bases that make up them: adenine nucleotide - nitrogenous base adenine; guanine nucleotide nitrogenous base guanine; cytosine nucleotide nitrogenous base cytosine; thymine nucleotide nitrogenous base thymine.
Combining two strands of DNA into one molecule
Nucleotides A, G, C and T of one chain are connected, respectively, to nucleotides T, C, G and A of the other chain hydrogen bonds. Two hydrogen bonds are formed between A and T, and three hydrogen bonds are formed between G and C (A=T, G≡C).
Pairs of bases (nucleotides) A – T and G – C are called complementary, i.e. mutually corresponding. Complementarity- this is the chemical and morphological correspondence of nucleotides to each other in paired DNA chains.
5 ’ 3 ’
1 2 3
3’ 5’
Rice. 12 Section of the DNA double helix. The structure of the nucleotide (1 – phosphoric acid residue; 2 – deoxyribose; 3 – nitrogenous base). Connecting nucleotides using hydrogen bonds.
Chains in a DNA molecule antiparallel, that is, they are directed in opposite directions, so that the 3’ end of one chain is located opposite the 5’ end of the other chain. Genetic information in DNA is written in the direction from the 5' end to the 3' end. This strand is called sense DNA,
because this is where the genes are located. The second thread – 3’–5’ serves as a standard for storing genetic information.
The relationship between the number of different bases in DNA was established by E. Chargaff in 1949. Chargaff found that in DNA of various species the amount of adenine is equal to the amount of thymine, and the amount of guanine is equal to the amount of cytosine.
E. Chargaff's rule:
in a DNA molecule, the number of A (adenine) nucleotides is always equal to the number of T (thymine) nucleotides or the ratio of ∑ A to ∑ T = 1. The sum of G (guanine) nucleotides is equal to the sum of C (cytosine) nucleotides or the ratio of ∑ G to ∑ C = 1;
the sum of purine bases (A+G) is equal to the sum of pyrimidine bases (T+C) or the ratio of ∑ (A+G) to ∑ (T+C)=1;
Method of DNA synthesis - replication. Replication is the process of self-duplication of a DNA molecule, carried out in the nucleus under the control of enzymes. Self-satisfaction of the DNA molecule occurs based on complementarity– strict correspondence of nucleotides to each other in paired DNA chains. At the beginning of the replication process, the DNA molecule unwinds (despirals) in a certain area (Fig. 13), and hydrogen bonds are released. On each of the chains formed after the rupture of hydrogen bonds, with the participation of the enzyme DNA polymerases the daughter strand of DNA is synthesized. The material for synthesis is free nucleotides contained in the cytoplasm of cells. These nucleotides are aligned complementary to the nucleotides of the two mother DNA strands. DNA polymerase enzyme attaches complementary nucleotides to the DNA template strand. For example, to a nucleotide A polymerase adds a nucleotide to the template strand T and, accordingly, to nucleotide G - nucleotide C (Fig. 14). Crosslinking of complementary nucleotides occurs with the help of an enzyme DNA ligases. Thus, two daughter strands of DNA are synthesized by self-duplication.
The resulting two DNA molecules from one DNA molecule are semi-conservative model, since they consist of an old mother and a new daughter chain and are an exact copy of the mother molecule (Fig. 14). The biological meaning of replication lies in the accurate transfer of hereditary information from the mother molecule to the daughter molecule.

Rice. 13 . Unspiralization of a DNA molecule using an enzyme
1

Rice. 14 . Replication is the formation of two DNA molecules from one DNA molecule: 1 – daughter DNA molecule; 2 – maternal (parental) DNA molecule.
The DNA polymerase enzyme can only move along the DNA strand in the 3’ –> 5’ direction. Since the complementary chains in a DNA molecule are directed in opposite directions, and the DNA polymerase enzyme can move along the DNA chain only in the 3’–>5’ direction, the synthesis of new chains proceeds antiparallel ( according to the principle of antiparallelism).
DNA localization site. DNA is found in the cell nucleus and in the matrix of mitochondria and chloroplasts.
The amount of DNA in a cell is constant and amounts to 6.6x10 -12 g.
Functions of DNA:
Storage and transmission of genetic information over generations to molecules and - RNA;
Structural. DNA is the structural basis of chromosomes (a chromosome is 40% DNA).
Species specificity of DNA. The nucleotide composition of DNA serves as a species criterion.
RNA, structure and functions.
General structure.
RNA is a linear biopolymer consisting of one polynucleotide chain. There are primary and secondary structures of RNA. The primary structure of RNA is a single-stranded molecule, and the secondary structure has the shape of a cross and is characteristic of tRNA.
Polymerity of the RNA molecule. An RNA molecule can contain from 70 nucleotides to 30,000 nucleotides. The nucleotides that make up RNA are the following: adenyl (A), guanyl (G), cytidyl (C), uracil (U). In RNA, the thymine nucleotide is replaced by uracil (U).
Structure of RNA nucleotide.
The RNA nucleotide includes 3 units:
nitrogenous base (adenine, guanine, cytosine, uracil);
monosaccharide - ribose (ribose contains oxygen at each carbon atom);
phosphoric acid residue.
Method of RNA synthesis - transcription. Transcription, like replication, is a reaction of template synthesis. The matrix is the DNA molecule. The reaction proceeds according to the principle of complementarity on one of the DNA strands (Fig. 15). The transcription process begins with despiralization of the DNA molecule at a specific site. The transcribed DNA strand contains promoter – a group of DNA nucleotides from which the synthesis of an RNA molecule begins. An enzyme attaches to the promoter RNA polymerase. The enzyme activates the transcription process. According to the principle of complementarity, nucleotides coming from the cell cytoplasm to the transcribed DNA chain are completed. RNA polymerase activates the alignment of nucleotides into one chain and the formation of an RNA molecule.
There are four stages in the transcription process: 1) binding of RNA polymerase to the promoter; 2) the beginning of synthesis (initiation); 3) elongation - growth of the RNA chain, i.e. nucleotides are sequentially added to each other; 4) termination – completion of mRNA synthesis.

Rice. 15 . Transcription scheme
1 – DNA molecule (double strand); 2 – RNA molecule; 3-codons; 4– promoter.
In 1972, American scientists - virologist H.M. Temin and molecular biologist D. Baltimore discovered reverse transcription using viruses in tumor cells. Reverse transcription– rewriting genetic information from RNA to DNA. The process occurs with the help of an enzyme reverse transcriptase.
Types of RNA by function
Messenger RNA (i-RNA or m-RNA) transfers genetic information from the DNA molecule to the site of protein synthesis - the ribosome. It is synthesized in the nucleus with the participation of the enzyme RNA polymerase. It makes up 5% of all types of RNA in a cell. mRNA includes from 300 nucleotides to 30,000 nucleotides (the longest chain among RNAs).
Transfer RNA (tRNA) transports amino acids to the site of protein synthesis, the ribosome. It has the shape of a cross (Fig. 16) and consists of 70–85 nucleotides. Its amount in the cell is 10-15% of the cell's RNA.

Rice. 16. Scheme of the structure of t-RNA: A–G – pairs of nucleotides connected by hydrogen bonds; D – place of amino acid attachment (acceptor site); E – anticodon.
3. Ribosomal RNA (r-RNA) is synthesized in the nucleolus and is part of ribosomes. Includes approximately 3000 nucleotides. Makes up 85% of the cell's RNA. This type of RNA is found in the nucleus, in ribosomes, on the endoplasmic reticulum, in chromosomes, in the mitochondrial matrix, and also in plastids.
Basics of cytology. Solving typical problems
Problem 1
How many thymine and adenine nucleotides are contained in DNA if 50 cytosine nucleotides are found in it, which is 10% of all nucleotides.
Solution. According to the rule of complementarity in the double strand of DNA, cytosine is always complementary to guanine. 50 cytosine nucleotides make up 10%, therefore, according to Chargaff’s rule, 50 guanine nucleotides also make up 10%, or (if ∑C = 10%, then ∑G = 10%).
The sum of the C + G nucleotide pair is 20%
Sum of nucleotide pair T + A = 100% – 20% (C + G) = 80%
In order to find out how many thymine and adenine nucleotides are contained in DNA, you need to make the following proportion:
50 cytosine nucleotides → 10%
X (T + A) →80%
X = 50x80:10=400 pieces
According to Chargaff's rule, ∑A= ∑T, therefore ∑A=200 and ∑T=200.
Answer: the number of thymine and adenine nucleotides in DNA is 200.
Problem 2
Thymine nucleotides in DNA make up 18% of the total number of nucleotides. Determine the percentage of other types of nucleotides contained in DNA.
Solution.∑Т=18%. According to Chargaff's rule ∑T=∑A, therefore the share of adenine nucleotides also accounts for 18% (∑A=18%).
The sum of the T+A nucleotide pair is 36% (18% + 18% = 36%). Per pair of GiC nucleotides there are: G+C = 100% –36% = 64%. Since guanine is always complementary to cytosine, their content in DNA will be equal,
i.e. ∑ Г= ∑Ц=32%.
Answer: guanine content, like cytosine, is 32%.
Problem 3
The 20 cytosine nucleotides of DNA make up 10% of the total number of nucleotides. How many adenine nucleotides are there in a DNA molecule?
Solution. In a double strand of DNA, the amount of cytosine is equal to the amount of guanine, therefore, their sum is: C + G = 40 nucleotides. We find total quantity nucleotides:
20 cytosine nucleotides → 10%
X (total number of nucleotides) →100%
X=20x100:10=200 pieces
A+T=200 – 40=160 pieces
Since adenine is complementary to thymine, their content will be equal,
i.e. 160 pieces: 2=80 pieces, or ∑A=∑T=80.
Answer: There are 80 adenine nucleotides in a DNA molecule.
Problem 4
Add the nucleotides of the right chain of DNA if the nucleotides of its left chain are known: AGA – TAT – GTG – TCT
Solution. The construction of the right strand of DNA along a given left strand is carried out according to the principle of complementarity - strict correspondence of nucleotides to each other: adenony - thymine (A-T), guanine - cytosine (G-C). Therefore, the nucleotides of the right strand of DNA should be as follows: TCT - ATA - CAC - AGA.
Answer: nucleotides of the right strand of DNA: TCT – ATA – TsAC – AGA.
Problem 5
Write down the transcription if the transcribed DNA chain has the following nucleotide order: AGA - TAT - TGT - TCT.
Solution. The mRNA molecule is synthesized according to the principle of complementarity on one of the chains of the DNA molecule. We know the order of nucleotides in the transcribed DNA chain. Therefore, it is necessary to build a complementary chain of mRNA. It should be remembered that instead of thymine, the RNA molecule contains uracil. Hence:
DNA chain: AGA – TAT – TGT – TCT
mRNA chain: UCU – AUA – ACA – AGA.
Answer: the nucleotide sequence of i-RNA is as follows: UCU – AUA – ACA – AGA.
Problem 6
Write down the reverse transcription, i.e., construct a fragment of a double-stranded DNA molecule based on the proposed fragment of i-RNA, if the i-RNA chain has the following nucleotide sequence:
GCG – ACA – UUU – UCG – TsGU – AGU – AGA
Solution. Reverse transcription is the synthesis of a DNA molecule based on the genetic code of mRNA. The mRNA encoding the DNA molecule has the following nucleotide order: GCH - ACA - UUU - UCG - TsGU - AGU - AGA. The DNA chain complementary to it is: CGC - TGT - AAA - AGC - GCA - TCA - TCT. Second DNA strand: HCH–ACA–TTT–TCG–CHT–AGT–AGA.
Answer: as a result of reverse transcription, two chains of the DNA molecule were synthesized: CGC - TTG - AAA - AGC - GCA - TCA and GCH - ACA - TTT - TCG - CGT - AGT - AGA.
Genetic code. Protein biosynthesis.
Gene– a section of a DNA molecule containing genetic information about the primary structure of one specific protein.
Exon-intron structure of a geneeukaryotes
promoter– a section of DNA (up to 100 nucleotides long) to which the enzyme attaches RNA polymerase, necessary for transcription;
2) regulatory zone– zone affecting gene activity;
3) structural part of a gene– genetic information about the primary structure of the protein.
A sequence of DNA nucleotides that carries genetic information about the primary structure of a protein - exon. They are also part of mRNA. A sequence of DNA nucleotides that does not carry genetic information about the primary structure of a protein – intron. They are not part of mRNA. During transcription, with the help of special enzymes, copies of introns are cut out from i-RNA and copies of exons are stitched together to form an i-RNA molecule (Fig. 20). This process is called splicing.

Rice. 20 . Splicing pattern (formation of mature mRNA in eukaryotes)
Genetic code - a system of nucleotide sequences in a DNA, or RNA, molecule that corresponds to the sequence of amino acids in a polypeptide chain.
Properties of the genetic code:
Triplety(ACA – GTG – GCH...)
The genetic code is triplet, since each of the 20 amino acids is encoded by a sequence of three nucleotides ( triplet, codon).
There are 64 types of nucleotide triplets (4 3 =64).
Uniqueness (specificity)
The genetic code is unambiguous because each individual nucleotide triplet (codon) codes for only one amino acid, or one codon always corresponds to one amino acid (Table 3).
Multiplicity (redundancy, or degeneracy)
The same amino acid can be encoded by several triplets (from 2 to 6), since there are 20 protein-forming amino acids and 64 triplets.
Continuity
Reading of genetic information occurs in one direction, from left to right. If one nucleotide is lost, then when read, its place will be taken by the nearest nucleotide from the neighboring triplet, which will lead to a change in genetic information.
Versatility
The genetic code is common to all living organisms, and the same triplets code for the same amino acid in all living organisms.
Has start and terminal triplets(starting triplet - AUG, terminal triplets UAA, UGA, UAG). These types of triplets do not code for amino acids.
Non-overlapping (discreteness)
The genetic code is non-overlapping, since the same nucleotide cannot simultaneously be part of two neighboring triplets. Nucleotides can belong to only one triplet, and if they are rearranged into another triplet, the genetic information will change.
Table 3 – Genetic code table
|
Codon bases |
|||||
Note: abbreviated names of amino acids are given in accordance with international terminology.
Protein biosynthesis
Protein biosynthesis – type of plastic exchange substances in the cell that occur in living organisms under the action of enzymes. Protein biosynthesis is preceded by matrix synthesis reactions (replication - DNA synthesis; transcription - RNA synthesis; translation - assembly of protein molecules on ribosomes). In the process of protein biosynthesis, there are 2 stages:
transcription
broadcast
During transcription, the genetic information contained in the DNA located in the chromosomes of the nucleus is transferred to an RNA molecule. Upon completion of the transcription process, mRNA enters the cell cytoplasm through pores in the nuclear membrane, is located between the 2 ribosomal subunits and participates in protein biosynthesis.
Translation is the process of translating the genetic code into a sequence of amino acids. Translation occurs in the cytoplasm of the cell on ribosomes, which are located on the surface of the ER (endoplasmic reticulum). Ribosomes are spherical granules with an average diameter of 20 nm, consisting of large and small subunits. The mRNA molecule is located between two ribosomal subunits. The translation process involves amino acids, ATP, mRNA, t-RNA, and the enzyme amino-acyl t-RNA synthetase.
Codon- a section of a DNA molecule, or mRNA, consisting of three sequentially located nucleotides, encoding one amino acid.
Anticodon– a section of a tRNA molecule, consisting of three sequentially located nucleotides and complementary to the codon of the iRNA molecule. The codons are complementary to the corresponding anticodons and are connected to them using hydrogen bonds (Fig. 21).
Protein synthesis begins with start codon AUG. From it the ribosome
moves along the mRNA molecule, triplet by triplet. Amino acids are supplied according to the genetic code. Their integration into the polypeptide chain on the ribosome occurs with the help of t-RNA. The primary structure of t-RNA (chain) transforms into a secondary structure that resembles a cross in shape, and at the same time the complementarity of nucleotides is preserved in it. At the bottom of the tRNA there is an acceptor site to which an amino acid is attached (Fig. 16). Activation of amino acids is carried out using an enzyme aminoacyl tRNA synthetase. The essence of this process is that this enzyme interacts with amino acid and ATP. In this case, a ternary complex is formed, represented by this enzyme, an amino acid and ATP. The amino acid is enriched with energy, activated, and acquires the ability to form peptide bonds with a neighboring amino acid. Without the process of amino acid activation, a polypeptide chain from amino acids cannot be formed.
The opposite, upper part of the tRNA molecule contains a triplet of nucleotides anticodon, with the help of which tRNA is attached to its complementary codon (Fig. 22).
The first t-RNA molecule, with an activated amino acid attached to it, attaches its anticodon to the i-RNA codon, and one amino acid ends up in the ribosome. Then the second tRNA is attached with its anticodon to the corresponding codon of the mRNA. In this case, the ribosome already contains 2 amino acids, between which a peptide bond is formed. The first tRNA leaves the ribosome as soon as it donates an amino acid to the polypeptide chain on the ribosome. Then the 3rd amino acid is added to the dipeptide, it is brought by the third tRNA, etc. Protein synthesis stops at one of the terminal codons - UAA, UAG, UGA (Fig. 23).

1 – mRNA codon; codonsUCGUCG; CUACUA; CGU -Central State University;
2– tRNA anticodon; anticodon GAT - GAT
Rice. 21 . Translation phase: the mRNA codon is attracted to the tRNA anticodon by the corresponding complementary nucleotides (bases)

The structure of RNA is less ordered. It is usually a single-stranded molecule, although the RNA of some viruses consists of two strands. But even such RNA is more flexible than DNA. Some regions in the RNA molecule are mutually complementary and, when the strand is bent, pair up to form double-stranded structures (hairpins). This primarily applies to transfer RNAs (tRNAs). Some bases in tRNA undergo modification after the molecule is synthesized. For example, sometimes methyl groups are added to them.
FUNCTION OF NUCLEIC ACIDS One of the main functions of nucleic acids is to determine the synthesis of proteins. Information about the structure of proteins encoded in the nucleotide sequence of DNA must be transmitted from one generation to another, and therefore its error-free copying is necessary, i.e. synthesis of exactly the same DNA molecule (replication).Replication and transcription. From a chemical point of view, nucleic acid synthesis is polymerization, i.e. sequential connection of building blocks. Nucleoside triphosphates serve as such blocks; the reaction can be represented as follows: The energy required for synthesis is released when pyrophosphate is removed, and the reaction is catalyzed by special enzymes called DNA polymerases.
The energy required for synthesis is released when pyrophosphate is removed, and the reaction is catalyzed by special enzymes called DNA polymerases. As a result of such a synthetic process, we would obtain a polymer with a random sequence of bases. However, most polymerases only work in the presence of a pre-existing template nucleic acid, which dictates which nucleotide will be added to the end of the chain. This nucleotide must be complementary to the corresponding nucleotide of the template, so that the new strand is complementary to the original one. By then using the complementary strand as a template, we obtain an exact copy of the original.
DNA consists of two mutually complementary strands. During replication, they diverge, and each of them serves as a template for the synthesis of a new chain:
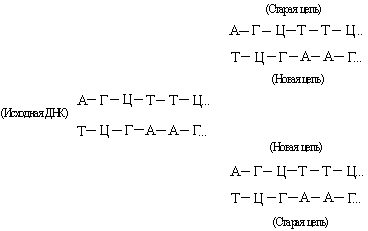 This creates two new double helices with the same base sequence as the original DNA. Sometimes the replication process “fails” and mutations occur (see also
HEREDITY).
As a result of DNA transcription, cellular RNAs (mRNA, rRNA and tRNA) are formed:
This creates two new double helices with the same base sequence as the original DNA. Sometimes the replication process “fails” and mutations occur (see also
HEREDITY).
As a result of DNA transcription, cellular RNAs (mRNA, rRNA and tRNA) are formed: They are complementary to one of the DNA strands and are a copy of the other strand, except that uracil takes the place of thymine. In this way, you can get many RNA copies of one of the DNA chains.In a normal cell, information is transmitted only in the direction of DNA® DNA and DNA ® RNA. However, other processes are also possible in cells infected with a virus: RNA® RNA and RNA ® DNA. The genetic material of many viruses is an RNA molecule, usually single-stranded. Having penetrated the host cell, this RNA is replicated to form a complementary molecule, on which, in turn, many copies of the original viral RNA are synthesized:
They are complementary to one of the DNA strands and are a copy of the other strand, except that uracil takes the place of thymine. In this way, you can get many RNA copies of one of the DNA chains.In a normal cell, information is transmitted only in the direction of DNA® DNA and DNA ® RNA. However, other processes are also possible in cells infected with a virus: RNA® RNA and RNA ® DNA. The genetic material of many viruses is an RNA molecule, usually single-stranded. Having penetrated the host cell, this RNA is replicated to form a complementary molecule, on which, in turn, many copies of the original viral RNA are synthesized: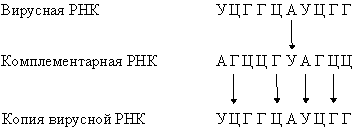 Viral RNA can be transcribed by the enzyme-
reverse transcriptase-
in DNA that is sometimes incorporated into the chromosomal DNA of the host cell. This DNA now carries viral genes, and after transcription, viral RNA can appear in the cell. So after long time, during which no virus is detected in the cell, it will reappear in it without re-infection. Viruses whose genetic material is inserted into the host cell's chromosome are often the cause of cancer.
Viral RNA can be transcribed by the enzyme-
reverse transcriptase-
in DNA that is sometimes incorporated into the chromosomal DNA of the host cell. This DNA now carries viral genes, and after transcription, viral RNA can appear in the cell. So after long time, during which no virus is detected in the cell, it will reappear in it without re-infection. Viruses whose genetic material is inserted into the host cell's chromosome are often the cause of cancer.
-
 April 17, 2015When a corrective alcohol return may be required
April 17, 2015When a corrective alcohol return may be required -
 April 17, 2015"Marble" cupcake: recipes and cooking methods
April 17, 2015"Marble" cupcake: recipes and cooking methods -
 April 17, 2015Recipe without sterilization with onion sautéing
April 17, 2015Recipe without sterilization with onion sautéing






